Alpaca 7B — качественная подделка ИИ ChatGPT, которая обошлась исследователям из Стэнфорда всего в $600
Alpaca 7B работает подобно ChatGPT, но построена на языковой модели с открытым кодом, для обучения которой понадобится всего $600.
Еще полгода назад за развитием крупных языковых моделей следили в основном исследователи, но запуск чат-бота OpenAI привлек внимание всего человечества. Оказалось, что машины могут общаться в способ, который практически не отличается от человеческого — пишут тексты или даже программные коды, и стремительно совершенствуются (вспомним недавний запуск GPT-4).
ИИ-гонки стартовали после того, как активно включились Google, Apple, Meta, Baidu и Amazon, и ныне языковые модели уже есть в наших поисковых системах и появятся в автомобилях, телефонах и телевизорах, а затем и в роботах.
Но как насчет языковой модели, которую можно создать самостоятельно за $600?
Исследовательская группа Стэнфордского университета взяла за основу языковую модель Meta LLaMA 7B с открытым кодом – самую маленькую и дешевую из доступных моделей LLaMA. Предварительно обученная на триллионе «токенов», эта модель имела определенные возможности, но значительно отставала от ChatGPT в большинстве задач.
Когда LLaMA 7B была запущена, исследователи попросили GPT-3.5 взять 175 пар инструкций, написанных человеком, и сгенерировать большее количество в том же стиле и формате, по 20 за раз. Процесс автоматизировали с помощью одного из полезных API OpenAI, и за короткое время у команды было около 52 000 образцов разговоров, которые можно было использовать при обучении модели LLaMA. Создание массива обучающих данных обошлось менее чем в $500.
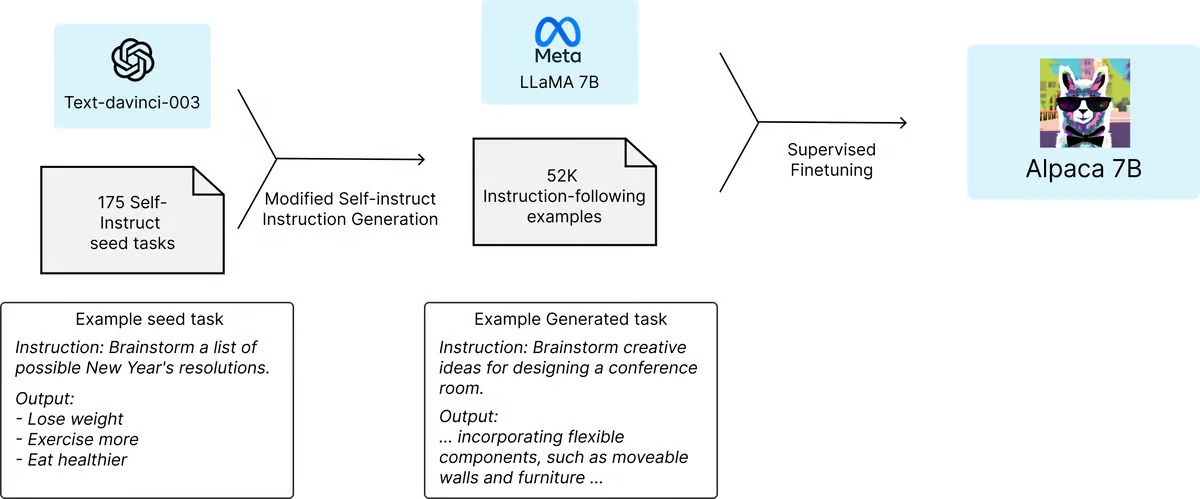
Эти данные впоследствии использовали для тонкой настройки LLaMA – трехчасовой процесс, происходивший на 8 моделях A100 на 80 ГБ, которые стоят менее $100 у большинства поставщиков облачных вычислений.
Далее модель, которую назвали Alpaca 7B, протестировали параллельно с ChatGPT в разных областях, включая электронную почту, социальные сети и инструменты производительности. Alpaca победила в 90 из этих тестов, а GPT – в 89.
«Мы были удивлены результатом, учитывая небольшой размер модели и скромный объем данных для выполнения инструкций. Кроме использования этого набора статических оценок, мы также тестировали Alpaca в интерактивном режиме и обнаружили, что она часто ведет себя подобно GPT-3.5 на различных входных данных. Мы признаем, что наша оценка может быть ограничена в масштабе и разнообразии», – пишет команда.
Исследователи говорят, что могли бы использовать еще меньше средств для оптимизации процесса. Стоит отметить, что желающие создать собственную ИИ-технологию, теперь получили доступ к гораздо более мощному GPT-4, а также к более мощным моделям LLaMA, которые можно использовать как основу.
Команда Стэнфордского университета опубликовала на Github 52 000 вопросов, использованных в исследовании, вместе с кодом для генерации дополнительных вопросов и кодом, который они использовали для тонкой настройки модели LLaMA. Отмечается, что исследователи «еще не настроили модель, чтобы она была безопасной и безвредной», и просит всех, кто устанавливает ее, отчитываться о выявленных проблемах безопасности и этики.
Что же может помешать созданию собственного ИИ-инструмента на основе языковых моделей OpenAI? Согласно условиям предоставления услуг компании, «нельзя использовать исходные данные Служб для разработки моделей, конкурирующих с OpenAI». Meta также позволяет использовать LLaMA только академическим исследователям по некоммерческим лицензиям — хотя, как мы сообщали, модель просочилась в сеть через неделю после анонса.
Другая группа утверждает, что можно вообще устранить расходы на облачные вычисления и завершить обучение за 5 часов на одной высококачественной видеокарте NVIDIA RTX 4090.
I don’t know what to make about this development. Alpaca is surprisingly very good. The claim here is the training can be done in 5 hours on a single RTX 4090. Have GPT-like models been democratized overnight?! https://t.co/ysfn5u6xwI
— Carlos E. Perez (@IntuitMachine) March 16, 2023
Источник: New Atlas, Stanford

{kind=link}