Помните, в 2015 году Google Фото принял двух темнокожих за горилл — нейросети Google (а также Apple, Amazon и Microsoft) здесь до сих пор бессильны
Несмотря на значительные достижения в области компьютерного зрения, Google по-прежнему боится повторить свою ошибку.
Курс
PR-менеджмент для тих, хто вже все вміє
Директорка з корпоративних комунікацій Kyivstar поділиться досвідом і секретами успіху
Хочу на курс

В мае 2015 года Google выпустила новый сервис для хранения фотографий, который впечатлял тем, что предлагал систему автоматической организации снимков – группировку по определенным категориям. Однако через несколько месяцев программа попала в скандал, когда разработчик программного обеспечения Джеки Алсине заметил, что она обозначила его с другом (обе темнокожие) – тегом «горилла».
Google впоследствии извинилась и удалила тег, но, как оказалось, он не доступен до сих пор – несмотря на большой прогресс в области искусственного интеллекта.
Журналисты NY Times решили проанализировать 44 изображения с помощью программы Google Фото, а также ее конкурентов Apple, Amazon и Microsoft – и проверить, как они сейчас реагируют на приматов.

Google Фото с легкостью обозначило кошек и кенгуру, и в целом большинство предложенных животных, за исключением горилл. Когда поиск расширили до бабуинов, шимпанзе, орангутангов – программа тоже не справилась, несмотря на то, что в коллекции журналистов были изображения каждого примата. Похожая проблема была у программы для фото от Apple – она могла точно находить снимки определенных животных, за исключением большинства приматов. Горилл программное обеспечение идентифицировало только в том случае, если на фото помещался текст (к примеру, для клейкой ленты бренда Gorilla Tape).


Microsoft OneDrive не обозначила ни одно из животных, в то время как Amazon Фото показала результаты почти для всех поисковых запросов.
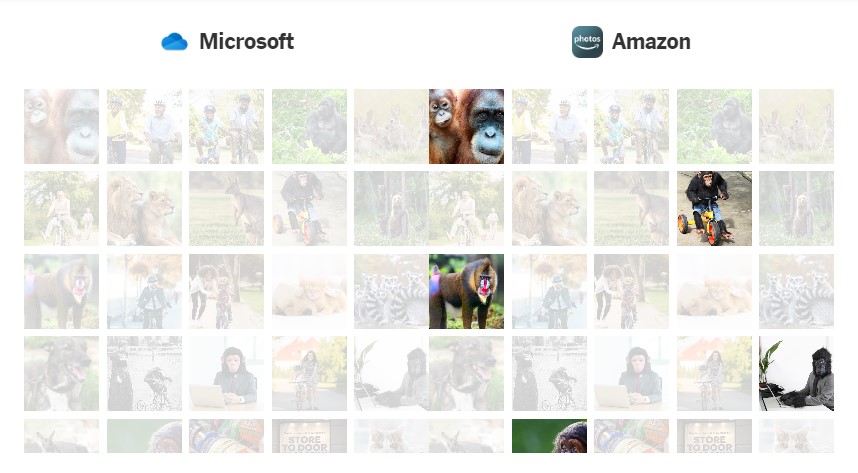
В конце концов, Google и Apple распознали одного примата, и это был лемур. Сам Джеки Алсине, который стал причиной страха техногиганта, выглядел очень удивленным и испуганным, узнав, что Google до сих пор не решила проблему.
Курс
ПРОДЮСУВАННЯ АРТПРОЄКТІВ
Оволодійте навичками створення професійних артпроєктів та реалізуйте свої найсміливіші творчі задуми!
Дізнатися про програму

«Общество слишком доверяет технологиям. Никогда не буду верить этому ИИ», — сказал Алсине.
Технологию компьютерного зрения сейчас используют для повседневных задач, таких как отправка оповещения, когда на порог дома был доставлен пакет; а также более весомых — например навигация автомобиля или поиск преступников.
Ошибки могут отображать расистские настроения среди тех, кто кодирует данные. Во время инцидента с гориллой два экс-сотрудника Google, которые работали над технологией, сказали, что компания просто не разместила достаточное количество фотографий темнокожих людей в коллекции изображений для обучения системы ИИ.
Хотя продукты компьютерного зрения и чат-боты с ИИ, такие как ChatGPT — разные вещи, они оба зависят от базовых массивов данных, обучающих программное обеспечение, и оба могут давать сбой из-за недостатков данных или предубеждений, включенных в их код. Microsoft, к примеру, пришлось ограничить возможность пользователей взаимодействовать с чат-ботом, встроенным в поисковую систему Bing, после того, как он провоцировал неприемлемые разговоры. Решение компании, как и ее конкурента Google, иллюстрирует общий отраслевой подход – отгораживать неисправные технологические функции, а не исправлять их.
Однако программы для фото — не единственные продукты, которые испытывают проблемы с обозначением темнокожих людей. Веб-камеры HP для отслеживания лица не могли обнаружить некоторых людей с темной кожей, а Apple Watch, согласно иску, не мог точно определить уровень кислорода в крови по цвету кожи. Это свидетельствует, что технические продукты не были предназначены для людей с более темной кожей с самого начала.
Google повторила свою ошибку много лет спустя, во время внутреннего тестирования камеры безопасности Nest — ее искусственный интеллект воспринимал некоторых темнокожих людей, как животных. Однако по словам человека, знакомого с инцидентом, в то время работавшего в Google, компания решила проблему до того, как пользователи получили доступ к продукту.
В 2019 году Google пыталась усовершенствовать функцию распознавания лиц для смартфонов Android, увеличив количество людей с темной кожей в своем наборе данных. Но подрядчики, которых Google наняла для сбора сканов лица, как сообщается, прибегли к странной тактике, чтобы компенсировать эту нехватку разнообразных данных: они нацелились на бездомных и студентов. Руководители Google тогда назвали инцидент «очень тревожным».
Маргарет Митчелл, исследовательница и соучредительница группы Google Ethical AI, которая присоединилась к компании после инцидента с гориллой, в недавнем интервью сказала, что она поддерживает решение компании удалить «метку горилл, по крайней мере на некоторое время».
«Вы должны подумать о том, как часто кому-нибудь понадобится обозначать гориллу, а не поддерживать вредные стереотипы. Польза не первышает потенциальный вред», — сказала Митчелл.
Apple отказалась предоставить комментарии, а в Amazon и Microsoft сказали, что компании постоянно стремятся улучшить свои продукты.
В настоящее время у Google есть более мощный продукт для анализа изображений — Google Lens. Хотя в 2018 году Wired обнаружил, что инструмент тоже не смог идентифицировать гориллу. Команда журналистов NY Times через 5 лет выявила схожие проблемы — Lens предлагал вероятную породу собаки в ответ на запрос с ее фото, но отказывался обозначать гориллу, шимпанзе, бабуина и орангутанга, и показывал только «визуальные совпадения» — фотографии, которые он считал похожими на оригинальное изображение.

 здесь до сих пор бессильны){kind=link}