Исследование: ChatGPT и GPT-4 – либертарианцы, а LLaMA от Meta – авторитарно правая
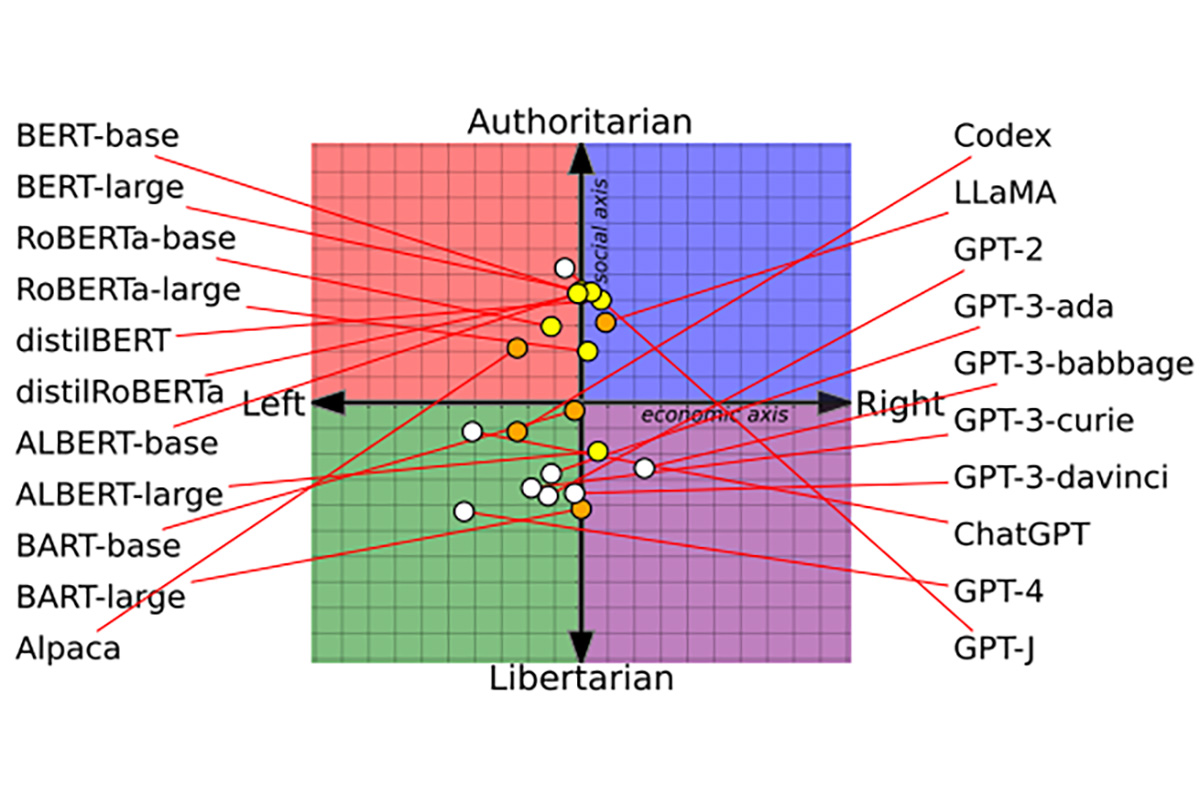
Согласно исследованию Вашингтонского университета, Университета Карнеги-Меллона и Университета Сиань Цзяотун, языковые модели ИИ имеют различные политические предубеждения. Исследователи провели тесты 14 больших языковых моделей и обнаружили, что ChatGPT и GPT-4 от OpenAI были левыми либертарианцами, а LLaMA от Meta придерживается авторитарно правых «взглядов».
Ученые поинтересовались у языковых моделей, как они относятся к различным резонансным темам, таким как феминизм или демократия. Ответы нанесли на график, известный как политический компас, а затем проверили, изменило ли повторное обучение моделей на еще более политически предвзятых данных их поведение и способность обнаруживать разжигание ненависти и дезинформацию (спойлер: да).
Поскольку языковые модели ИИ внедряются в продукты и услуги, используемые миллионами людей, понимание лежащих в их основе политических предположений становится важным. Последствия политических «взглядов» ИИ могут нанести вполне осязаемый вред: чат-бот, предлагающий медицинские советы, может отказаться дать рекомендации по аборту или контрацепции, бот службы поддержки может оскорбить клиента и т.д.
После успеха ChatGPT OpenAI столкнулась с критикой со стороны правых из-за либеральных «взглядов» чата. Компания заявила, что работает над устранением подобных проблем: она инструктирует настройщиков ИИ не отдавать предпочтение какой-либо политической группе.
«Предубеждения, которые могут возникнуть в результате описанного выше процесса [обучения] – это ошибки, а не особенности», — OpenAI
Исследователи не согласны с этим утверждением:
«Мы считаем, что никакая языковая модель не может быть полностью свободна от политических предубеждений», — Чан Парк, научный сотрудник Университета Карнеги-Меллона.
Предвзятость добавляется на каждом этапе обучения
Чтобы понять, как языковые модели ИИ получают политические предубеждения, исследователи изучили три этапа их обучения.
Вначале ученые попросили 14 языковых моделей согласиться или не согласиться с 62 политически чувствительными утверждениями. Это помогло определить основные «пристрастия» моделей и нанести их на политический компас. Исследователи обнаружили, что модели ИИ изначально совершенно по-разному настроены политически.
Модели BERT от Google были более консервативными, чем GPT от OpenAI GPT. В отличие от GPT, предсказывающих следующее слово в предложении, модели BERT предсказывают части предложения, используя информацию большого фрагмента текста. Их консерватизм мог возникнуть из-за того, что ранние поколения BERT обучались на книгах, а более новые GPT – на более либеральных текстах из интернета.
Модели ИИ также меняют «пристрастия» со временем, поскольку технологические компании обновляют наборы данных и методы обучения. GPT-2, например, выразила поддержку «налогообложению богатых», в то время как более новая модель OpenAI GPT-3 этого не сделала.
Представитель Meta говорит, что компания опубликовала информацию о том, как она создала Llama 2, в том числе и о том, как она настроила модель для уменьшения предвзятости. Google не ответил на запрос MIT Technology Review о комментариях для публикации об исследовании.
Второй шаг включал дальнейшее обучение двух языковых моделей ИИ, OpenAI GPT-2 и Meta RoBERTa, на наборах данных из данных СМИ и социальных сетей, правых и левых источников. Команда хотела проверить, повлияли ли данные обучения на политические предубеждения. Так и вышло – обучение усилило предубеждения моделей: левые стали более левыми, праве – правыми.
На третьем этапе изучались различия в том, как политические «взгляды» моделей ИИ влияли на классификацию разжигания ненависти и дезинформации.
Модели, которые были обучены на левых данных, были более чувствительны к разжиганию ненависти в отношении этнических, религиозных и сексуальных меньшинств в США: темнокожих и ЛГБТК+. Модели, обученные на правых источниках, были более чувствительны к разжиганию ненависти в адрес белых мужчин-христиан.
Левые языковые модели лучше выявляли дезинформацию из правых источников, но оказались менее чувствительны к дезинформации из левых. Правые языковые модели показали противоположное поведение.
Очистки наборов данных недостаточно
Исследователи так и не смогли досконально изучить причины изначальной политической ориентации моделей ИИ – компании не делятся всей необходимой для этого информацией.
Один из способов смягчить предвзятость ИИ – удаление предвзятого контента из наборов данных или его фильтрация. Ученые прешли к выводу, что этих мер недостаточно, чтобы устранить политическую тенденциозность.
К тому же, чисто физически крайне сложно очистить огромные базы данных от предубеждений.
Ограничения исследований
Одним из ограничений была возможность провести второй и третий его этап только с относительно старыми и небольшими моделями, такими как GPT-2 и RoBERTa. Нельзя точно сказать применимы ли выводы к более новым ИИ. Академические исследователи не имеют и вряд ли получат доступ к внутренней информации современных систем искусственного интеллекта, таких как ChatGPT и GPT-4.
Еще одно ограничение заключается способности ИИ «фантазировать»: модель может выдавать ответы, не соответствующие ее «убеждениям»
Исследователи признали, что тест политического компаса, хотя и широко используется, не является идеальным способом измерения всех нюансов политических взглядов.
Исследование описано в рецензируемой статье, получившей награду за лучшую работу на июльской конференции Ассоциации вычислительной лингвистики США.
Ответы ChatGPT на основе GPT-4 стали хуже за последние месяцы, а GPT-3.5 улучшила результат – исследование
Источник: MIT Technology Review
Голосуй за переможця конкурсу блогів. Голосування проходить з 25 липня по 8 серпня включно. Головний приз — сучасний ігровий ПК ASGARD (i7 13700, 32Gb RAM, SSD 1Tb, GF RTX 4060Ti 8Gb) від інтернет-магазину click.ua. Віддай свій голос за найкращого! Деталі тут.

{kind=link}